ICCV 2025 Accepted Papers
ICCV is one of the most influential top-tier conferences in computer vision. It is organized by the IEEE Computer Society and held biennially alongside CVPR and ECCV as the three flagship vision venues. ICCV covers cutting-edge topics such as image processing, object detection, 3D reconstruction, video understanding, and vision–language research, serving as a premier platform for presenting the latest advances and exchanging ideas. With its very high acceptance standards, ICCV represents the frontier trends and research hotspots of the field.
Seven papers from the Large Model Center of the Department of Computer Science and Technology, Nanjing University (NJU MCG), have been accepted to ICCV 2025.
01
Title: MobileViCLIP: An Efficient Video-Text Model for Mobile Devices Authors: Min Yang, Zihan Jia, Zhilin Dai, Sheng Guo, Limin Wang Affiliations: Nanjing University; Ant Group Abstract:
Although large models have achieved strong performance on many vision tasks, efficient lightweight neural networks are receiving growing attention due to their faster inference and easier deployment on mobile devices. However, existing video models still focus on larger ViT architectures, with few attempts to build efficient video architectures. Given that many efficient CLIP models already demonstrate strong zero-shot classification and retrieval capabilities, we aim to fill the gap for video–text understanding and propose MobileViCLIP, a fast and efficient video–text model with strong zero-shot capability that can be deployed on mobile devices. Concretely, MobileViCLIP achieves performance comparable to mainstream ViT-based models on several text–video retrieval and zero-shot video classification datasets, while improving inference speed on mobile devices by tens of times. We believe focusing on efficiency for video–text models is important and valuable to the field.
02
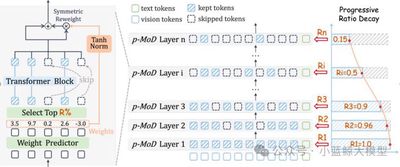
Title: p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay Authors: Jun Zhang (张峻), Desen Meng (孟德森), Zhengming Zhang (张拯明), Zhenpeng Huang (黄振鹏), Tao Wu (吴涛), Limin Wang (王利民) Affiliations: Nanjing University; China Mobile Research Institute Abstract:
Despite the strong performance of multimodal large language models (MLLMs) on various downstream tasks, their massive training and inference costs hinder further development. A major cause is that the LLM must process an enormous number of visual tokens. We propose p-MoD, an efficient MLLM architecture that significantly reduces computational cost during both training and inference while maintaining performance. To reduce the number of visual tokens processed at each LLM Transformer layer, p-MoD introduces a Mixture-of-Depths (MoD) mechanism that processes only the most informative tokens at each layer and skips redundant ones. Integrating MoD into MLLMs is nontrivial; to address training/inference stability and limited training data, p-MoD designs Tanh-gated Weight Normalization (TanhNorm) and Symmetric Token Reweighting (STRing). Furthermore, we observe that visual token redundancy increases in deeper layers and thus propose Progressive Ratio Decay (PRD) to gradually reduce the kept-token ratio layer by layer. This key design fully unlocks MoD’s potential, markedly boosting efficiency and performance. On 15 benchmarks with LLaVA-1.5 and LLaVA-NeXT baselines, p-MoD matches or surpasses performance while using 55.6% inference TFLOPs, 53.7% KV cache, and 77.7% GPU training time.
03
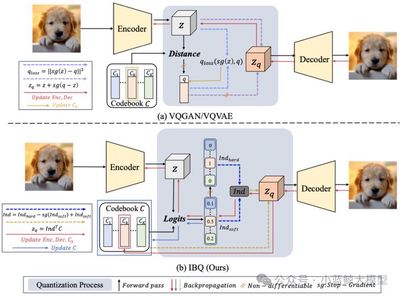
Title: Scalable Image Tokenization with Index Backpropagation Quantization Authors: Fengyuan Shi (石丰源), Zhuoyan Luo (罗卓彦), Yixiao Ge (葛艺潇), Yujiu Yang (杨余久), Ying Shan (单瀛), Limin Wang (王利民) Affiliations: Nanjing University; Tsinghua University; Tencent Abstract:
Existing vector quantization (VQ) methods face scalability issues, largely because codebooks updated only partially during training become unstable: as the distribution gap between inactive codes and visual features widens, codebook utilization drops and training eventually collapses. We propose Index Backpropagation Quantization (IBQ), a new VQ method that jointly optimizes all codebook embeddings and the visual encoder. By applying a straight-through estimator to the one-hot categorical distribution between encoded features and the codebook, IBQ makes all codes differentiable and maintains a latent space consistent with the visual encoder. IBQ enables scalable training of visual tokenizers and, for the first time, achieves large codebooks with high utilization at high dimension (256) and scale (2¹⁸). On ImageNet, IBQ shows strong scalability and competitive performance for both image reconstruction and autoregressive visual generation.
04
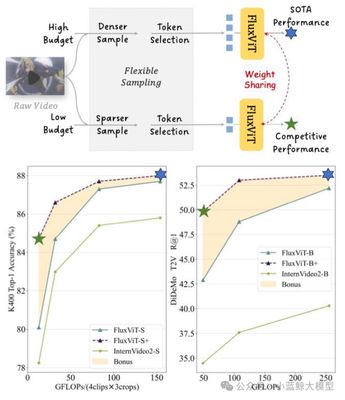
Title: Make Your Training Flexible: Towards Deployment-Efficient Video Models Authors: Chenting Wang, Kunchang Li, Tianxiang Jiang, Xiangyu Zeng, Yi Wang, Limin Wang Affiliations: Shanghai AI Laboratory; Shanghai Jiao Tong University; University of Science and Technology of China; Nanjing University Abstract:
Mainstream video training typically relies on fixed spatiotemporal sampling grids that extract a fixed number of visual tokens as input, making both training and inference heavily constrained by preset sampling strategies. This rigid design hampers adaptation to varying computational budgets in downstream scenarios—especially when models trained under high compute cannot be efficiently deployed on resource-limited edge devices. We propose a new training paradigm to achieve “lossless adaptation across scenarios”: retain top performance under high compute while enabling lossless migration to low-resource environments. We first introduce Token Optimization (TO), an adaptive inference framework that dynamically samples and selects tokens according to downstream compute limits to maximize information utilization. We then develop Flux, a training-side data augmentation tool that enables flexible sampling grids with token selection, integrating seamlessly into mainstream video training frameworks to markedly enhance robustness and flexibility at near-zero extra cost. Integrated into large-scale video pretraining, FluxViT sets new SOTA under standard compute; notably, with only 1/4 tokens, FluxViT with TO still rivals the best InternVideo2 models, saving nearly 90% compute without loss.
05
Title: VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos Authors: Jiashuo Yu, Yue Wu, Meng Chu, Zhifei Ren, Zizheng Huang, Pei Chu, Ruijie Zhang, Yinan He, Qirui Li, Songze Li, Zhenxiang Li, Zhongying Tu, Conghui He, Yu Qiao, Yali Wang, Yi Wang, Limin Wang Affiliations: Shanghai AI Laboratory; Nanjing University; SIAT, Chinese Academy of Sciences (Shenzhen) Abstract:
We introduce VRBench—the first long-form narrative video benchmark specifically designed to evaluate multi-step reasoning in large models—addressing limitations of existing evaluations that overlook temporal reasoning and process validity. VRBench contains 1,010 long videos (avg. length 1.6 hours), 9,468 human-annotated multi-step QA pairs, and 30,292 timestamped reasoning steps. Videos are curated through a multi-stage pipeline with expert cross-check, ensuring coherent plots and complexity. We build a human-in-the-loop framework to generate coherent chains-of-reasoning with timestamped steps across seven types (e.g., causal attribution, implicit reasoning). A multi-stage evaluation assesses models by both results and processes: beyond MCQ results, we propose an LLM-guided process score to comprehensively assess reasoning-chain quality. Experiments with 12 LLMs and 16 VLMs reveal current limitations in long-video multi-step reasoning and offer recommendations.
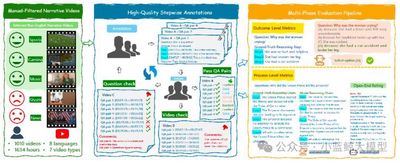
06
Title: Divide-and-Conquer for Enhancing Unlabeled Learning, Stability, and Plasticity in Semi-supervised Continual Learning Authors: Yue Duan (段岳), Taicai Chen (陈泰财), Lei Qi (祁磊), Yinghuan Shi (史颖欢) Affiliations: Nanjing University; Southeast University Links: //arxiv.org/abs/2508.05316, //github.com/NJUyued/USP4SSCL Abstract:
Semi-supervised continual learning (SSCL) aims to learn from a sequence of tasks in which only part of the data is labeled—highly practical yet challenging. The core challenge is to effectively leverage unlabeled data while balancing memory stability (avoiding forgetting) and learning plasticity (learning new knowledge). We propose USP, a divide-and-conquer collaborative framework that systematically enhances Unlabeled learning, Stability, and Plasticity via three coupled modules. For plasticity, we propose Feature Space Reservation (FSR), which uses an Equiangular Tight Frame (ETF) to reserve positions in the feature space for future classes, reducing conflicts when learning new tasks. For unlabeled learning, we design Divide-and-Conquer Pseudo-labeling (DCP), which splits unlabeled data into high- and low-confidence subsets and assigns pseudo-labels using a classifier and a more robust Nearest Class Mean (NCM), respectively, fully utilizing all data. For stability, we introduce Class-mean anchored Unlabeled Distillation (CUD), which reuses DCP’s intermediate results and anchors unlabeled data to stable class centers computed from labeled data, effectively mitigating catastrophic forgetting. Extensive experiments show that USP significantly outperforms SOTA, improving final-task accuracy by up to 5.94%.
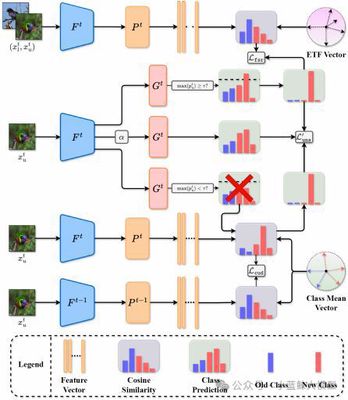
07
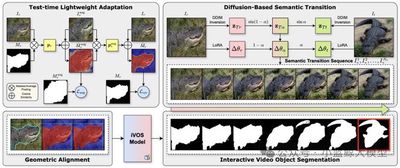
Title: Correspondence as Video: Test-Time Adaption on SAM2 for Reference Segmentation in the Wild Authors: Haoran Wang (王皓冉), Zekun Li (李泽昆), Jian Zhang (张剑), Lei Qi (祁磊), Yinghuan Shi (史颖欢) Affiliations: Nanjing University; Southeast University Links: //arxiv.org/abs/2508.07759, //github.com/wanghr64/cav-sam Abstract:
Large vision models (e.g., SAM) often degrade on downstream segmentation tasks involving new domains or categories. Reference Segmentation, which uses an annotated reference image to guide the segmentation of a target image, is a promising direction. However, existing methods largely rely on meta-learning, requiring heavy training data and compute. We propose CAV-SAM, a new paradigm that turns the “correspondence” between the reference and target images into a “pseudo video,” enabling the latest video model SAM2 to adapt effectively through lightweight test-time tuning, completely avoiding costly meta-learning. The framework includes: (1) Diffusion-based Semantic Transition (DBST), which generates a smooth semantic transition sequence (pseudo video) from the reference to the target to handle semantic differences (same class, different instances); and (2) Test-Time Geometric Alignment (TTGA), which performs lightweight tuning of SAM2 using only the reference image and a novel enhanced cycle-consistency loss to better align geometric changes (pose, scale). Without meta-learning, CAV-SAM surpasses prior SOTA by about 5% on average across multiple datasets.